


Last update: @12/13/2022

문자 인코딩(character encoding)이란?
•
컴퓨터는 내부적으로 숫자만 저장할 수 있기 때문에, 문자를 저장하려면 문자에 대응되는 숫자를 약속해놓아야 함
◦
따라서 모니터에 나타나는 문자와 컴퓨터 내부적으로 처리하는 숫자를 1대 1로 대응해놓은 문자표에 따라 컴퓨터가 요리조리 바꾸는 일을 문자 인코딩/디코딩(character encoding/decoding)이라고 함
•
이런 문자 인코딩 방식에 너무 여러가지 약속이 존재해서 전 세계 개발자들을 괴롭히고 있음
ASCII(American Standard Code for Information Interchange)
1963년에 발표된 미국 표준 문자표
•
7비트 아스키
: 이기 때문에 0부터 127까지 128개의 숫자에 영어와 특수문자를 대응해놓은 약속.
◦
ASCII 코드는 보통 이 7비트 아스키 코드를 말함. 8비트 컴퓨터에서는 앞의 한자리가 0임
◦
초기에 8비트를 사용하지 않은 이유는, 당시 8비트 컴퓨터가 귀했고, 나머지 1비트를 오류 검출용으로 사용했기 때문임
◦
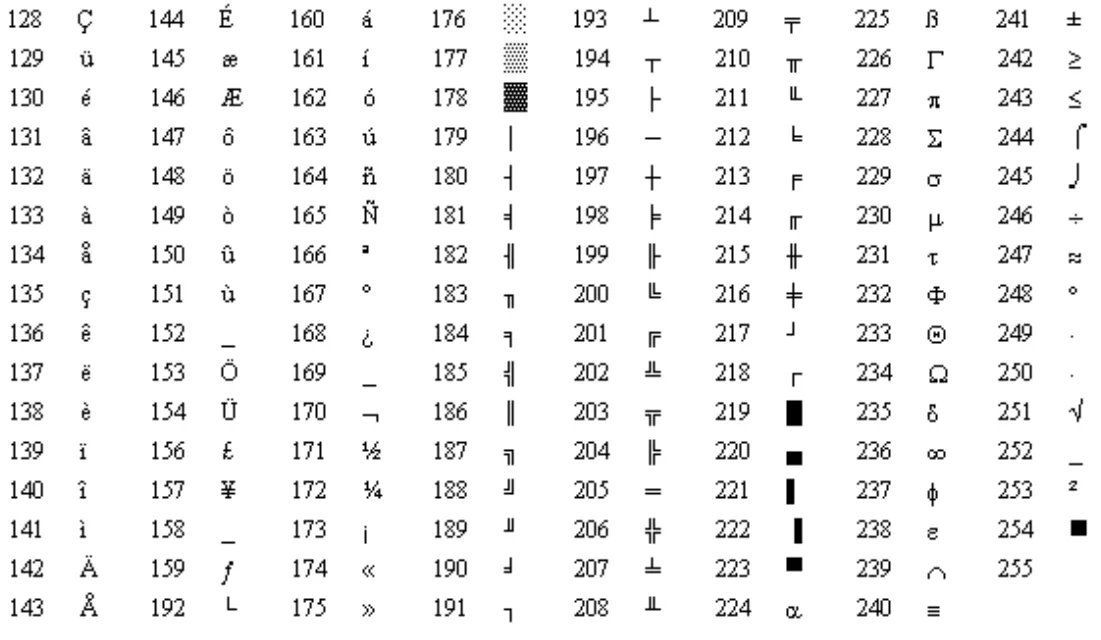
이후 8비트 컴퓨터가 상용화되면서, 맨 앞 비트에 1이 붙은 127개의 추가 문자를 표현할 수 있게 됨
•
8비트 아스키: 8비트(1바이트를 모두 써서 표현한 아스키. 128개가 뽀너스로 존재함)
◦
종류
▪
ISO-8859 문자표
•
ISO-8859-1(Latin-1): 영어, 프랑스어 등 서유럽어
◦
HTML을 위한 기본 문자표
•
이외에 지역별로 ISO-8859-2~11까지 존재
▪
IBM 코드 페이지
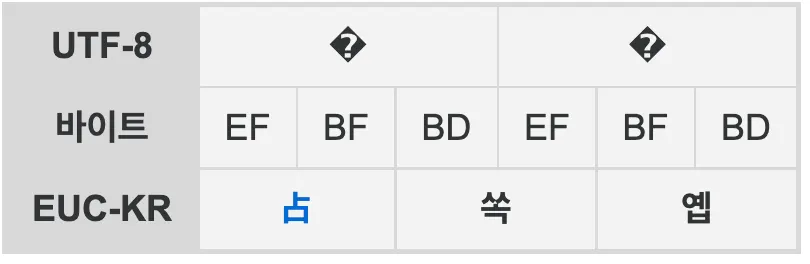
영어 이외의 언어로 인한 새로운 코드표의 등장(유니코드, EUC-KR, CP949)
•
하지만 컴퓨터가 보급되면서 1바이트(8비트)면 충분한 라틴어계열 언어 이외에도 코드표가 필요하게 됨
•
특히 라틴어 계열은 알파벳으로 퉁치면 되는데, 동아시아로 오니까 한자, 한국어 등 문자가 너무 많아 난리가 남(현대 한글: 11,172 개, 한자: 10만 개 이상)
•
그래서 기존 1바이트에 1바이트를 더 추가해서 128번째~65,535()번째 코드표에 각 언어별로 코드표를 만듦(한자는 1바이트가 더 필요했지만 타협을 봄)
◦
Microsoft는 이런 2바이트 이상의 코드 체계를 Multi Byte Character Set(MBCS)이라고 부르기도 함
한글 코드표의 변천사 KS X 1001 → EUC-KR → CP949
•
한글은 1987년 KS X 1001(옛 이름 KS C 5601)이라는 2,350글자만 채택해서 지원함
•
KS X 1001을 기반한 문자 인코딩 방식이 EUC-KR임(ISO-2022-KR도 있긴 함. 과거 인터넷 메일에서 쓰던 문자 인코딩 방식)
◦
EUC-KR은 KS X 1001 와 KS X 1003(옛 이름 KS C 5636)을 기반으로 하는 8비트 문자 인코딩
▪
EUC는 Extended Unix Code의 약자
▪
KS X 1003은 ASCII에서 역슬래시(\) 만 원화(₩)로 대치된 문자표임. 즉, EUC-KR은 사실상 ASCII 코드 기반 위에 한글 2,350자와 특수문자, 한자 등을 추가한 문자표인 것
•
MS에서 1995년에 EUC-KR에 나머지 한글 8,822자(11,172자 - 2,350자)를 모조리 추가하여 CP949(Code Page 949)를 만듦
◦
기존 2,350자 뒤에 붙이다보니 가나다 순서가 지켜지지 않아 뒤죽박죽 되면서 코드값만으로는 정렬이 제대로 안 되는 문제 등이 있음
◦
IBM에서 만든 동명의 문자표인 CP949도 있음
▪
EUC-KR 영역을 제외하곤 전혀 호환되지 않고, 거의 쓰이지도 않음
▪
자바에서는 IBM의 코드페이지를 CP949로, MS의 코드페이지를 MS949로 구분해놓았기 때문에 혼동하기 쉬움
유니코드(Unicode)
•
각 언어별로 코드표를 만들다보니 한 페이지에 두 개 이상의 언어를 표현할 수가 없었고, 2바이트 코드표에도 한계가 옴. 그래서 전 세계 모든 문자, 기호 등을 겹치지 않도록 1:1 대응하는 1~4바이트 코드표를 만들게 됨
•
유니코드는 1988년에 설립된 유니코드 컨소시엄에서 1991년 발표한 대응 문자 코드표
◦
문자 코드표의 정식 이름은 ISO/IEC 10646 Universal Character Set
•
문자코드표와 인코딩 방식은 다름. 코드표는 숫자(=키=코드포인트=인덱스)와 문자(값)가 1:1로 매핑된 형태의 테이블을 말함. 즉, 아스키코드로 표현할 수 없는 문자들까지 포함해 유니코드라는 이름 아래 전 세계의 모든 문자를 특정 숫자(키)와 1:1로 매핑한 것임
•
현재 약 개의 공간을 사용하고 있고, 한자를 제외한 전 세계 대부분의 문자가 유니코드에 담겨있음
•
U+(16진수 숫자) 식으로 표기함. 가끔 16진수 표기 관례를 따라 0x를 대신 붙여 표시하기도 함
유니코드 문자 평면(펼치기)
유니코드 표현 방법(인코딩 방식)
•
일단 문자별로 코드는 정해졌고, 이를 어떤 식으로 표현할 지에 대한 방법이 인코딩 방식임
◦
사실 글자 하나 하나에 대응하는 숫자를 저장하고, 읽어올 때 숫자에 해당하는 문자를 출력하면 특별히 인코딩 방식이랄 것이 없음. ASCII, EUC-KR, CP949 등의 문자표는 이런 식으로 인코딩/디코딩을 하기 때문에 인코딩 방식이랄 것에 신경을 쓰지 않아도 되고, 그냥 문자표의 이름이 곧 인코딩 방식이 됨
◦
하지만 숫자의 범위가 4바이트로 커지면서 문제가 시작됨. 모든 문자가 4바이트를 전부 요구하지 않기 때문임
▪
예를 들어 알파벳 A는 4바이트 코드로 00000000 00000000 00000000 01000001 인데, 앞의 3바이트가 불필요함
◦
따라서 인코딩, 디코딩 시 메모리, 네트워크 등 자원이 낭비됨. 이를 해결하기 위해 여러 인코딩 방식들이 고안된 것임
UCS(Universal Character Set)
•
아주 단순하게 몇 바이트로 데이터를 끊어 해석할 지를 정해놓고, 해당 바이트 범위 이하의 문자만 쓰는 방법
◦
UCS-2: 비록 모든 유니코드를 담을 수는 없지만 현실적으로 대부분의 문자를 표현할 수 있는 2바이트의 문자표만 사용해서 인코딩/디코딩 하는 방식
▪
데이터를 절반 아낄 수 있지만 3바이트 이상 필요한 문자들은 사용할 수 없음
◦
UCS-4: 4바이트를 모두 사용하는 문자표
▪
모든 문자를 표현할 수 있지만 데이터가 낭비됨
UTF(Universal Coded Character Set + Transformation Format)
•
이름 그대로 문자표로 유니코드를 사용하면서, 그것을 전송하는 방법을 정의한 포맷
•
예를 들어 1바이트 문자 하나와 2바이트 문자 하나가 3개의 바이트로, 낭비 없이 표현이 돼있다고 보자
첫번째 두번째 세번째
A B C
Shell
복사
◦
이 경우 AB를 하나의 2바이트 문자로 해석할 지, BC를 하나의 2바이트 문자로 해석할 지 어떻게 알 수 있을까? 이 규칙을 정한 것이 바로 UTF-n. 즉 디코더가 한 문자의 시작과 끝을 구별할 수 있도록 규칙을 정한 것
•
몇 비트단위로 사용해서 코드를 표현할 것인가를 나타냄
◦
UTF-8: 1바이트씩 늘려가며 코드를 나타냄. 1~6바이트를 이용해 유니코드를 표현
▪
문자 코드의 길이에 따라 1바이트(8비트)씩 늘려가며 표현하는 방법
▪
예를 들어 3바이트짜리 문자인 것을 디코더에게 알려주려면 가장 맨 앞의 숫자에 자기가 몇 바이트 문자의 머리(대장)인지를 표시하면 좋을 것임. 예를 들어 길이가 2바이트인 문자는 무조건 110으로 시작하도록 설정하면 디코더는 2바이트를 잘라서 하나의 문자로 해석하는 것
First code point | Last code point | Byte 1 | Byte 2 | Byte 3 | Byte 4 | Code points |
U+0000 | U+007F | 0xxxxxxx | 128 | |||
U+0080 | U+07FF | 110xxxxx | 10xxxxxx | 1920 | ||
U+0800 | U+FFFF | 1110xxxx | 10xxxxxx | 10xxxxxx | 61440 | |
U+10000 | U+10FFFF | 11110xxx | 10xxxxxx | 10xxxxxx | 10xxxxxx | 1048576 |
•
1바이트 문자(아스키)는 무조건 0으로 시작
•
꼬리문자는 10으로 시작하고(중복되기 때문에 아스키를 제외하고 가장 짧은 식별자를 사용한듯)
•
2바이트 문자는 110, 3바이트 문자는 1110, 4바이트 문자는 11110을 사용
•
여기서 의문점 하나, 한글은 2바이트 코드라 3바이트의 UTF의 16비트 자리에 딱 들어가는데, 다른 문자들은 자리가 남으면 어떻게 될까?
◦
아래에서 보다시피, 앞의 남는 공간에 padding bit를 채워넣음

◦
그렇다면 사실상 패딩비트도 고정값이라고 보여짐
◦
UTF-16(in windows, java): 16bit씩 늘려가며 코드를 나타냄. 2~4바이트를 이용해 유니코드 표현
▪
유니코드가 2바이트였던 초창기에는 UTF-16으로 모든 문자를 나타낼 수 있었음(BMP 영역)
▪
2000년대 이후 2바이트로는 부족해짐
▪
2바이트 이하 문자(BMP 문자)들은 2바이트로 처리하고, 그보다 크면 4바이트로 처리함
▪
엔디안(Endian)
•
바이트를 저장하는 배열의 순서를 정하는 방법을 말함
•
걸리버 여행기에 달걀을 뭉툭한 쪽(big-end)을 깨냐 뾰족한 쪽(little-end)를 깨냐를 두고 big-endian과 little-endian으로 파가 나뉜데서 유래함
•
둘 중 어느 방법을 쓰냐는 것은 상황에 따라 유동적이기 때문에 계속 논란의 대상이 됨
•
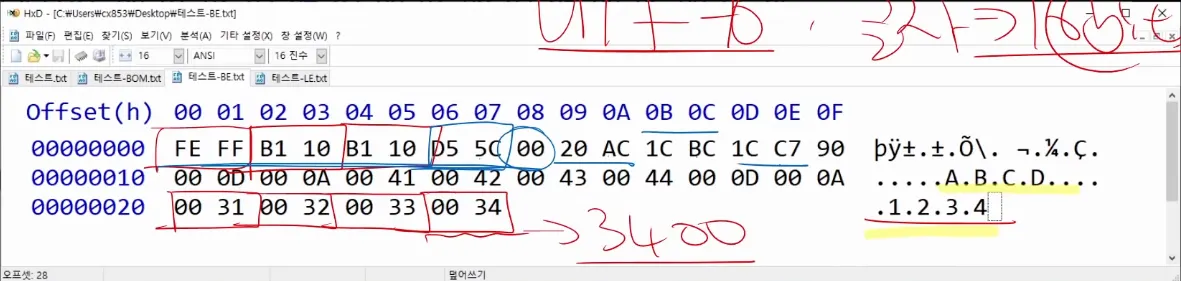
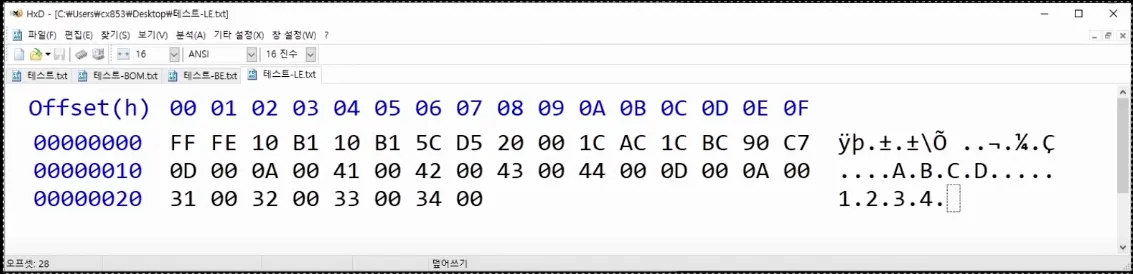
정방향(오른쪽)으로 저장하면 빅엔디안(BE), 역방향으로 저장하면 리틀엔디안(LE)임
◦
BE는 디버깅이 쉬움
◦
LE는 처리속도가 빠름
•
x86 아키텍쳐가 LE를 쓰고 이를 인텔 포멧이라고함. 따라서 대부분은 LE를 씀
•
네트워크에서는 주소를 BE로 씀(Network Byte Order, NBO)
•
미들 엔디안도 있음
•
엔디안을 표시하는 마크가 Byte order mark임
◦
유니코드 U+FEFF는 폭이 0이면서 줄바꿈을 하지 않는 공백문자를 뜻함
◦
BE는 FEFF, LE는 FFFE로 표시해서 텍스트에 영향을 주지 않고 엔디안을 나타낼 수 있음.
◦
UTF-32(in unix): 32bit로 코드를 나타냄. 4바이트를 이용해 유니코드 1:1대응
▪
4바이트를 모두 사용하는 상남자식 인코딩 방식
•
사실상 UTF-16과 UCS-2, UTF-32와 UCS-4는 서로 같다고 볼 수 있지만 unicode 3.1 이후부터 차이점이 생김
URL 인코딩
•
URL에는 아스키 코드에 있는 문자만 사용할 수 있기 때문에 유니코드 문자를 URL을 통해 전송하려면 유니코드를 아스키코드로 바꿔주는 URL 인코딩을 해야함
•
보통 UTF-8을 통해 인코딩 된 16진수 세 개 각각에 %를 붙여 전송함
•
우리가 브라우저 주소창에서 보는 문자는 %인코딩을 하기 전 모습을 브라우저가 보여주는 것. 내부적인 통신은 %인코딩을 통해 이루어짐
